Max Berggren
Data Scientist, Stockholm.
25+ years of creative tech work
Currently: Myrspoven
Previously: Dagens Nyheter
Currently: Myrspoven
Previously: Dagens Nyheter
AO News
Breaking News aggregator that collects the worlds news push notifications, translates and aggregates. Industry standard for most news rooms 2023.
🚀 Rocket Name Ideas
Service to come up with great domain names. Open source.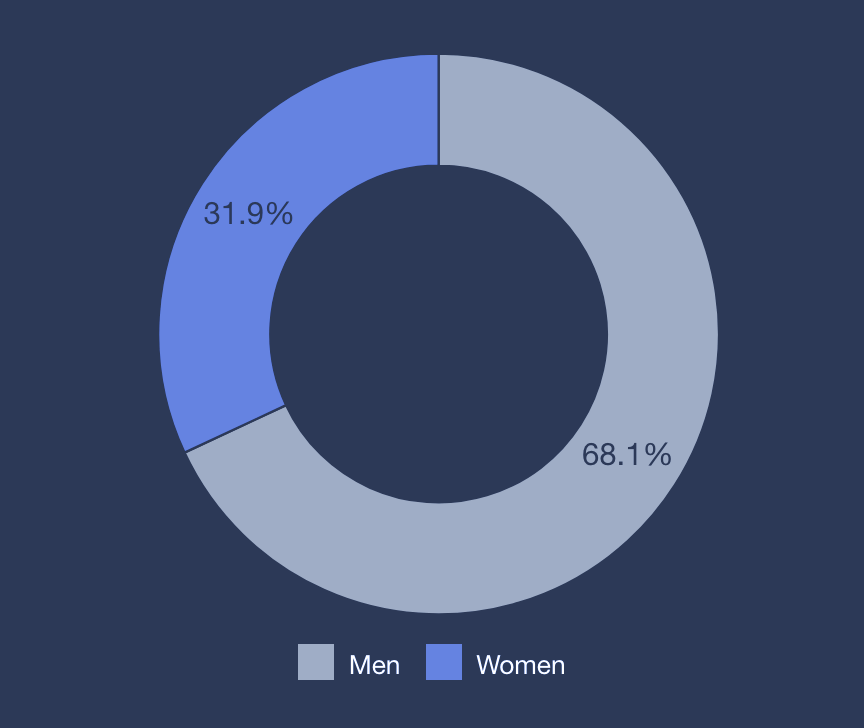
Prognosis
Collecting gender representation statistics for the news. Copied 🖤 by Financial Times and used by newsrooms around the world since 2015.